
[ad_1]
Αφηρημένη
Κάθε μέρα στο Roblox, 70 εκατομμύρια χρήστες ασχολούνται με εκατομμύρια εμπειρίες, συνολικά 16 δισεκατομμύρια ώρες ανά τρίμηνο. Αυτή η αλληλεπίδραση δημιουργεί μια λίμνη δεδομένων κλίμακας petabyte, η οποία εμπλουτίζεται για σκοπούς ανάλυσης και μηχανικής μάθησης (ML). Η σύνδεση πινάκων γεγονότων και διαστάσεων στη λίμνη δεδομένων μας απαιτεί μεγάλη κατανάλωση πόρων, επομένως για να βελτιστοποιήσουμε αυτό και να μειώσουμε την ανακάτεμα δεδομένων, υιοθετήσαμε τα φίλτρα Learned Bloom [1]—Έξυπνες δομές δεδομένων που χρησιμοποιούν ML. Με την πρόβλεψη της παρουσίας, αυτά τα φίλτρα περιορίζουν σημαντικά τα δεδομένα σύνδεσης, βελτιώνοντας την απόδοση και μειώνοντας το κόστος. Στην πορεία, βελτιώσαμε επίσης τις αρχιτεκτονικές των μοντέλων μας και δείξαμε τα σημαντικά οφέλη που προσφέρουν για τη μείωση των ωρών μνήμης και CPU για επεξεργασία, καθώς και αύξηση της λειτουργικής σταθερότητας.
Εισαγωγή
Στη λίμνη δεδομένων μας, οι πίνακες γεγονότων και οι κύβοι δεδομένων χωρίζονται προσωρινά για αποτελεσματική πρόσβαση, ενώ οι πίνακες διαστάσεων δεν διαθέτουν τέτοια διαμερίσματα και η σύνδεσή τους με πίνακες δεδομένων κατά τη διάρκεια των ενημερώσεων απαιτεί πόρους. Ο χώρος κλειδιού της ένωσης καθοδηγείται από τη χρονική κατάτμηση του πίνακα γεγονότων που ενώνεται. Οι οντότητες ιδιοτήτων που υπάρχουν σε αυτό το χρονικό διαμέρισμα είναι ένα μικρό υποσύνολο αυτών που υπάρχουν σε ολόκληρο το σύνολο δεδομένων διαστάσεων. Ως αποτέλεσμα, η πλειονότητα των ανακατεμένων δεδομένων διαστάσεων σε αυτές τις ενώσεις τελικά απορρίπτεται. Για να βελτιστοποιήσουμε αυτή τη διαδικασία και να μειώσουμε την περιττή ανακάτεμα, σκεφτήκαμε να χρησιμοποιήσουμε Φίλτρα Bloom σε διαφορετικά κλειδιά σύνδεσης, αλλά αντιμετώπισε προβλήματα με το μέγεθος του φίλτρου και το αποτύπωμα μνήμης.
Για να τα αντιμετωπίσουμε, εξερευνήσαμε Έμαθα φίλτρα Bloom, μια λύση που βασίζεται σε ML που μειώνει το μέγεθος του φίλτρου Bloom διατηρώντας παράλληλα χαμηλά ποσοστά ψευδώς θετικών. Αυτή η καινοτομία ενισχύει την αποτελεσματικότητα των λειτουργιών σύνδεσης μειώνοντας το υπολογιστικό κόστος και βελτιώνοντας τη σταθερότητα του συστήματος. Το παρακάτω σχηματικό απεικονίζει τις συμβατικές και βελτιστοποιημένες διαδικασίες σύνδεσης στο κατανεμημένο υπολογιστικό μας περιβάλλον.
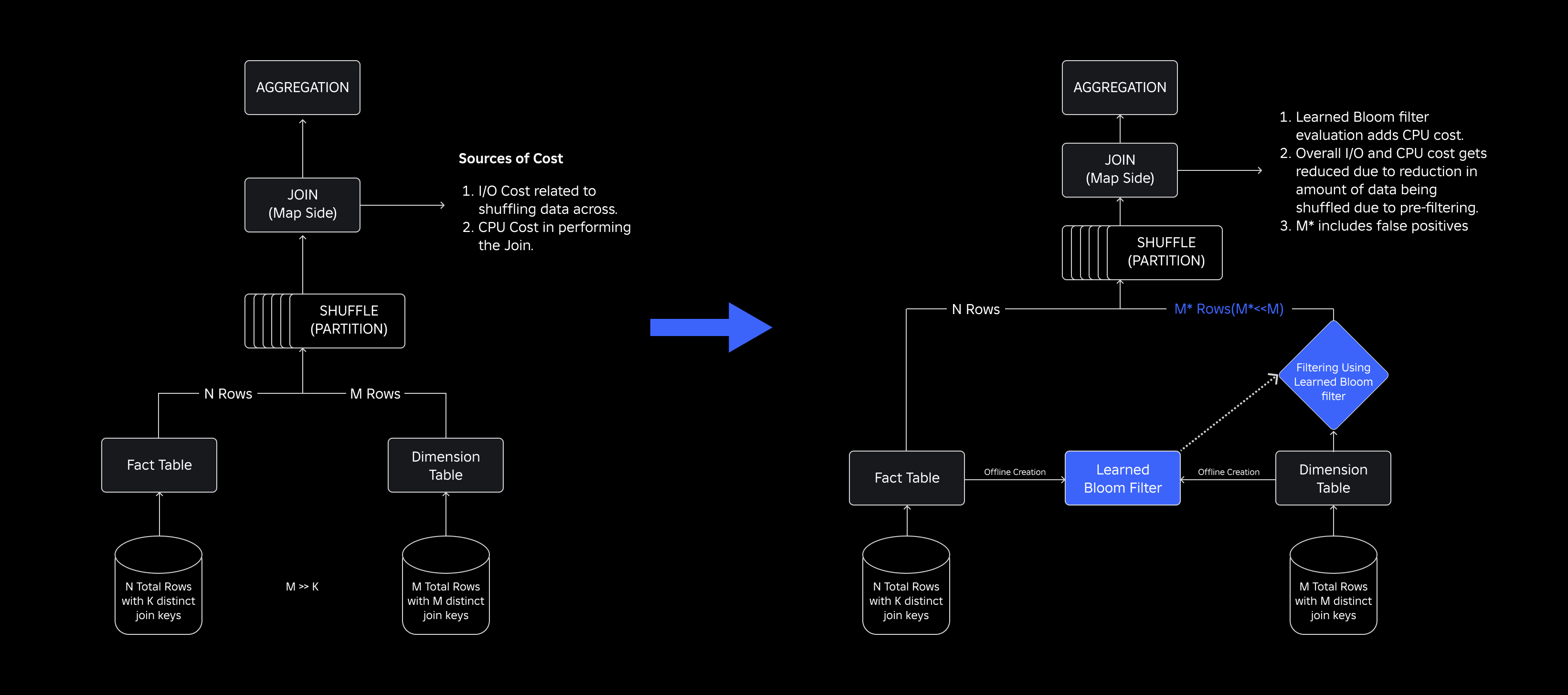
Βελτίωση της αποτελεσματικότητας σύνδεσης με φίλτρα μαθημένης Bloom
Για να βελτιστοποιήσουμε τη σύνδεση μεταξύ των πινάκων γεγονότων και διαστάσεων, υιοθετήσαμε την εφαρμογή Learned Bloom Filter. Κατασκευάσαμε ένα ευρετήριο από τα κλειδιά που υπάρχουν στον πίνακα γεγονότων και στη συνέχεια αναπτύξαμε το ευρετήριο για να προ-φιλτράρουμε δεδομένα διαστάσεων πριν από τη λειτουργία σύνδεσης.
Εξέλιξη από τα παραδοσιακά φίλτρα άνθισης στα μαθημένα φίλτρα άνθισης
Ενώ ένα παραδοσιακό φίλτρο Bloom είναι αποτελεσματικό, προσθέτει 15-25% επιπλέον μνήμης ανά κόμβο εργαζόμενου που χρειάζεται να το φορτώσει για να πετύχει το επιθυμητό ποσοστό ψευδώς θετικών. Αλλά με την αξιοποίηση των Learned Bloom Filters, πετύχαμε σημαντικά μειωμένο μέγεθος ευρετηρίου, διατηρώντας το ίδιο ψευδώς θετικό ποσοστό. Αυτό οφείλεται στη μετατροπή του φίλτρου Bloom σε πρόβλημα δυαδικής ταξινόμησης. Οι θετικές ετικέτες υποδηλώνουν την παρουσία τιμών στο ευρετήριο, ενώ οι αρνητικές σημαίνουν ότι απουσιάζουν.
Η εισαγωγή ενός μοντέλου ML διευκολύνει τον αρχικό έλεγχο τιμών, ακολουθούμενο από ένα εφεδρικό φίλτρο Bloom για την εξάλειψη των ψευδών αρνητικών. Το μειωμένο μέγεθος προέρχεται από τη συμπιεσμένη αναπαράσταση του μοντέλου και τον μειωμένο αριθμό κλειδιών που απαιτούνται από το εφεδρικό φίλτρο Bloom. Αυτό το διακρίνει από τη συμβατική προσέγγιση Bloom Filter.
Ως μέρος αυτής της εργασίας, δημιουργήσαμε δύο μετρήσεις για την αξιολόγηση της προσέγγισης Learned Bloom Filter: το τελικό μέγεθος σειριακού αντικειμένου του ευρετηρίου και την κατανάλωση CPU κατά την εκτέλεση των ερωτημάτων σύνδεσης.
Πλοήγηση στις προκλήσεις υλοποίησης
Η αρχική μας πρόκληση ήταν να αντιμετωπίσουμε ένα εξαιρετικά προκατειλημμένο σύνολο δεδομένων εκπαίδευσης με λίγα κλειδιά πίνακα διαστάσεων στον πίνακα γεγονότων. Με αυτόν τον τρόπο, παρατηρήσαμε μια επικάλυψη περίπου ενός στα τρία πλήκτρα μεταξύ των πινάκων. Για να το αντιμετωπίσουμε, αξιοποιήσαμε την προσέγγιση του φίλτρου άνθισης που εκμάθησε με σάντουιτς [2]. Αυτό ενσωματώνει ένα αρχικό παραδοσιακό φίλτρο Bloom για να εξισορροπήσει εκ νέου την κατανομή των δεδομένων, αφαιρώντας την πλειονότητα των κλειδιών που έλειπαν από τον πίνακα γεγονότων, εξαλείφοντας ουσιαστικά τα αρνητικά δείγματα από το σύνολο δεδομένων. Στη συνέχεια, μόνο τα κλειδιά που περιλαμβάνονται στο αρχικό φίλτρο Bloom, μαζί με τα ψευδώς θετικά, προωθήθηκαν στο μοντέλο ML, που συχνά αναφέρεται ως «μαθημένος χρησμός». Αυτή η προσέγγιση οδήγησε σε ένα καλά ισορροπημένο σύνολο δεδομένων εκπαίδευσης για το μαθημένο μαντείο, ξεπερνώντας αποτελεσματικά το ζήτημα της προκατάληψης.
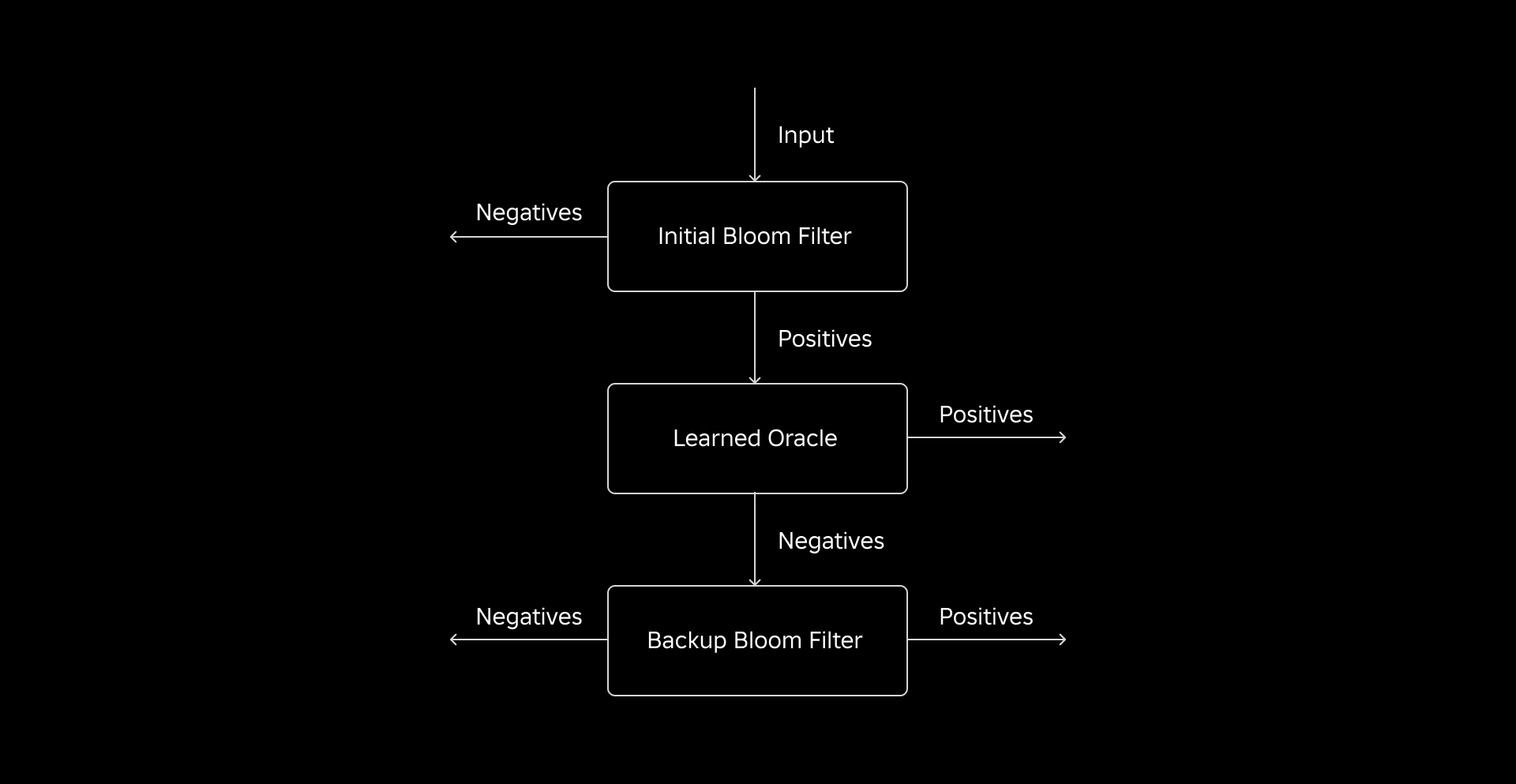
Η δεύτερη πρόκληση επικεντρώθηκε στην αρχιτεκτονική μοντέλων και τα χαρακτηριστικά εκπαίδευσης. Σε αντίθεση με το κλασικό πρόβλημα των διευθύνσεων URL ηλεκτρονικού ψαρέματος (phishing). [1], τα κλειδιά συμμετοχής μας (τα οποία στις περισσότερες περιπτώσεις είναι μοναδικά αναγνωριστικά για χρήστες/εμπειρίες) δεν ήταν εγγενώς ενημερωτικά. Αυτό μας οδήγησε να εξερευνήσουμε χαρακτηριστικά διάστασης ως πιθανά χαρακτηριστικά μοντέλου που μπορούν να βοηθήσουν στην πρόβλεψη εάν μια οντότητα διάστασης υπάρχει στον πίνακα γεγονότων. Για παράδειγμα, φανταστείτε έναν πίνακα γεγονότων που περιέχει πληροφορίες συνεδρίας χρήστη για εμπειρίες σε μια συγκεκριμένη γλώσσα. Η γεωγραφική θέση ή το χαρακτηριστικό προτίμησης γλώσσας της ιδιότητας χρήστη θα ήταν καλοί δείκτες για το εάν ένας μεμονωμένος χρήστης είναι παρών στον πίνακα γεγονότων ή όχι.
Η τρίτη πρόκληση – η καθυστέρηση συμπερασμάτων – απαιτούσε μοντέλα που ελαχιστοποιούσαν τα ψευδώς αρνητικά και παρείχαν γρήγορες απαντήσεις. Ένα μοντέλο δέντρου με ενίσχυση κλίσης ήταν η βέλτιστη επιλογή για αυτές τις βασικές μετρήσεις και κλαδέψαμε το σύνολο χαρακτηριστικών του για να εξισορροπηθεί η ακρίβεια και η ταχύτητα.
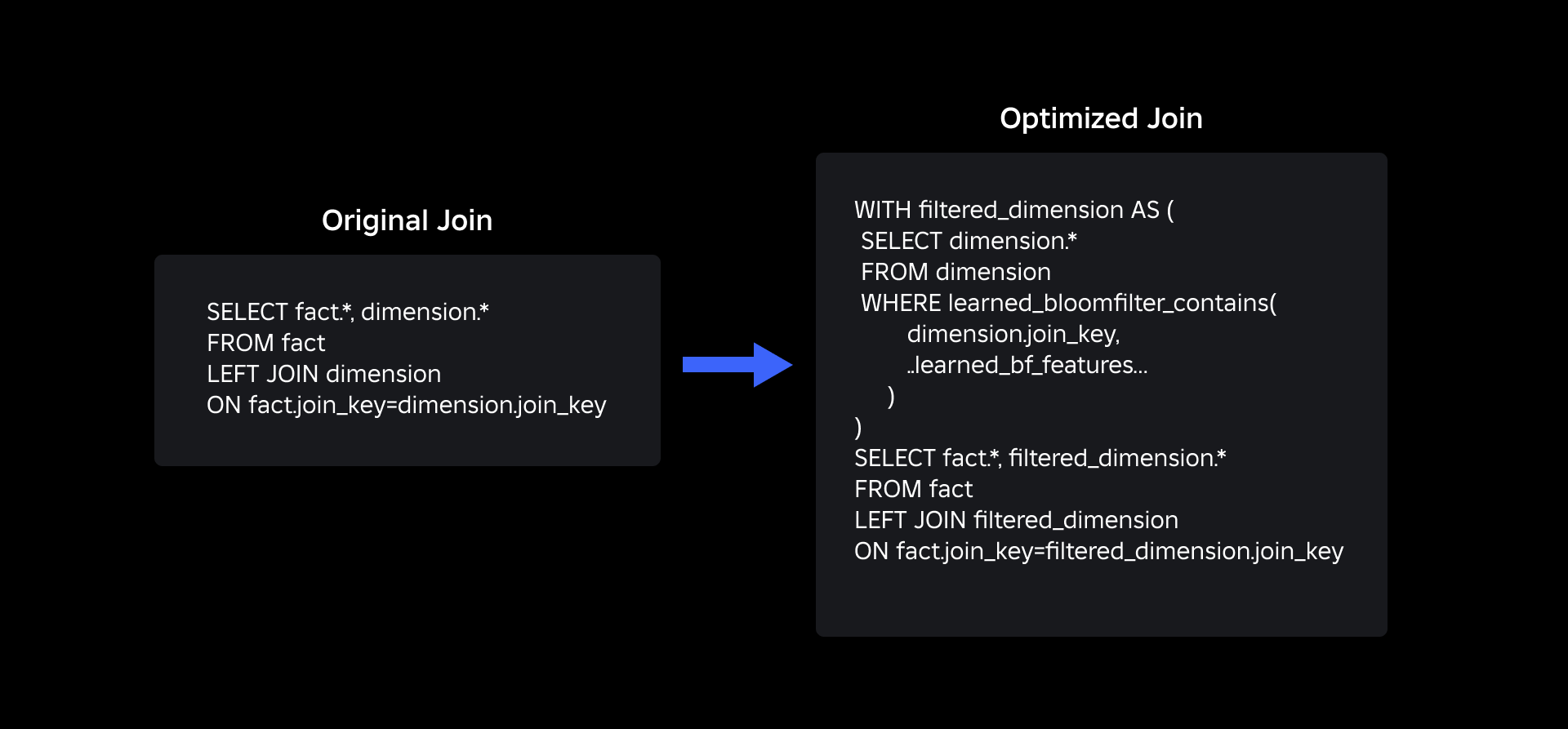
Το ενημερωμένο μας ερώτημα συμμετοχής χρησιμοποιώντας τα μαθημένα φίλτρα Bloom είναι όπως φαίνεται παρακάτω:
Αποτελέσματα
Εδώ είναι τα αποτελέσματα των πειραμάτων μας με τα φίλτρα Learned Bloom στη λίμνη δεδομένων μας. Τα ενσωματώσαμε σε πέντε φόρτους εργασίας παραγωγής, καθένας από τους οποίους διέθετε διαφορετικά χαρακτηριστικά δεδομένων. Το πιο δαπανηρό υπολογιστικά μέρος αυτών των φόρτων εργασίας είναι η ένωση μεταξύ ενός πίνακα γεγονότων και ενός πίνακα διαστάσεων. Ο βασικός χώρος των πινάκων γεγονότων είναι περίπου το 30% του πίνακα διαστάσεων. Αρχικά, συζητάμε πώς το Learned Bloom Filter ξεπέρασε τα παραδοσιακά Bloom Filters από την άποψη του τελικού σειριακού μεγέθους αντικειμένου. Στη συνέχεια, δείχνουμε βελτιώσεις απόδοσης που παρατηρήσαμε ενσωματώνοντας τα Learned Bloom Filters στους αγωγούς επεξεργασίας του φόρτου εργασίας μας.
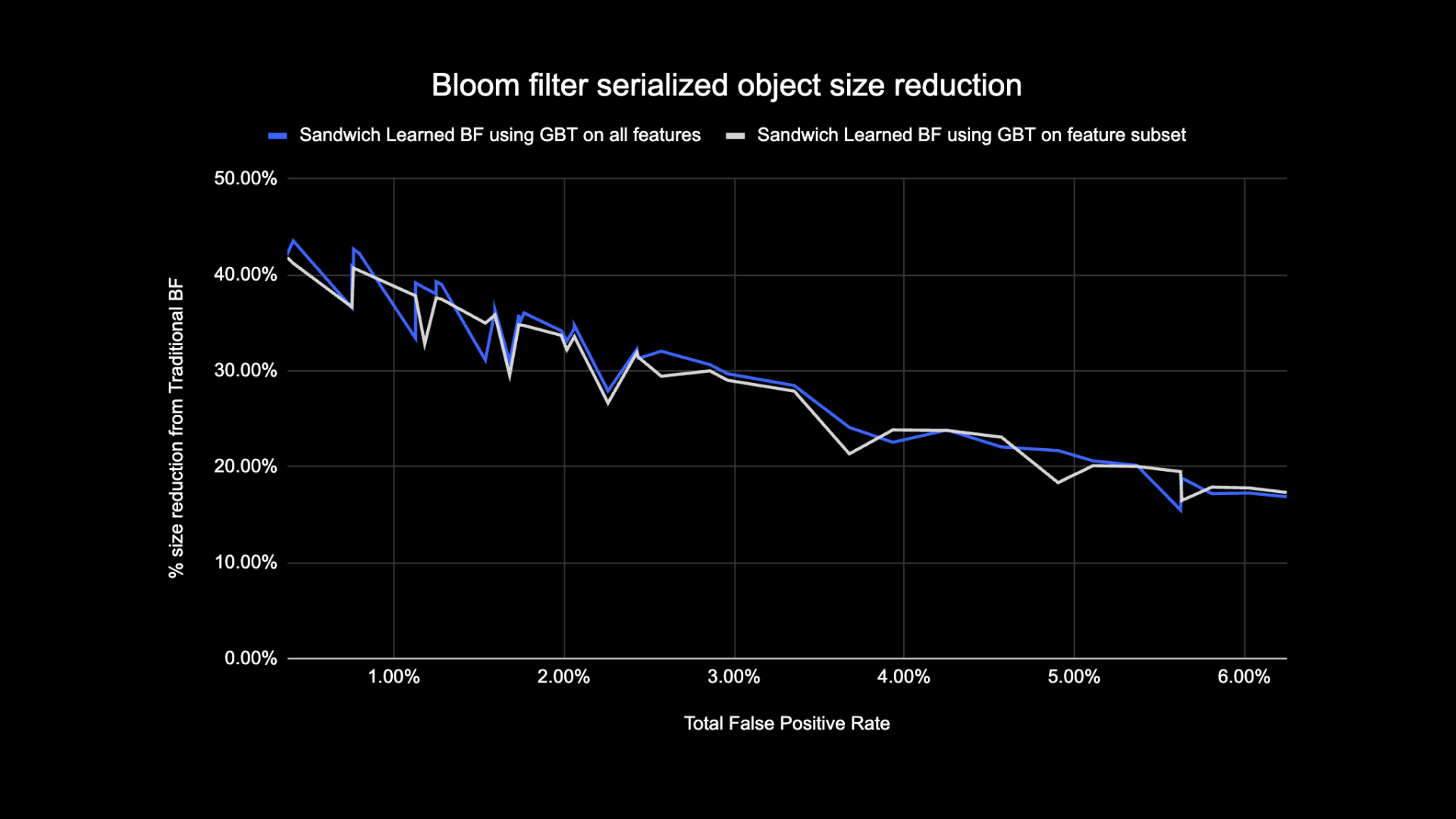
Σύγκριση μεγέθους φίλτρου εκμάθησης Bloom
Όπως φαίνεται παρακάτω, όταν εξετάζουμε ένα δεδομένο ποσοστό ψευδώς θετικών, οι δύο παραλλαγές του μαθημένου φίλτρου Bloom βελτιώνουν το συνολικό μέγεθος του αντικειμένου κατά 17-42% σε σύγκριση με τα παραδοσιακά φίλτρα Bloom.
Επιπλέον, χρησιμοποιώντας ένα μικρότερο υποσύνολο χαρακτηριστικών στο μοντέλο που βασίζεται σε δέντρο με ενισχυμένη κλίση, χάσαμε μόνο ένα μικρό ποσοστό βελτιστοποίησης, ενώ συνάγαμε πιο γρήγορα τα συμπεράσματα.
Αποτελέσματα χρήσης φίλτρου Bloom
Σε αυτήν την ενότητα, συγκρίνουμε την απόδοση των συνδέσεων που βασίζονται σε φίλτρο Bloom με εκείνη των κανονικών συνδέσεων σε διάφορες μετρήσεις.
Ο παρακάτω πίνακας συγκρίνει την απόδοση του φόρτου εργασίας με και χωρίς τη χρήση των Learned Bloom Filters. Ένα φίλτρο εκμάθησης άνθισης με 1% συνολική πιθανότητα ψευδώς θετικών καταδεικνύει την παρακάτω σύγκριση, ενώ διατηρεί την ίδια διαμόρφωση συμπλέγματος και για τους δύο τύπους σύνδεσης.

Πρώτον, διαπιστώσαμε ότι η εφαρμογή Bloom Filter ξεπέρασε την κανονική σύνδεση έως και 60% σε ώρες CPU. Παρατηρήσαμε μια αύξηση στη χρήση της CPU του βήματος σάρωσης για την προσέγγιση Learned Bloom Filter λόγω του πρόσθετου υπολογισμού που δαπανήθηκε για την αξιολόγηση του φίλτρου Bloom. Ωστόσο, το προφιλτράρισμα που έγινε σε αυτό το βήμα μείωσε το μέγεθος των δεδομένων που ανακατεύονταν, γεγονός που βοήθησε στη μείωση της CPU που χρησιμοποιήθηκε από τα κατάντη βήματα, μειώνοντας έτσι τις συνολικές ώρες CPU.
Δεύτερον, τα Learned Bloom Filters έχουν περίπου 80% λιγότερο συνολικό μέγεθος δεδομένων και περίπου 80% λιγότερα συνολικά byte τυχαίας αναπαραγωγής γραμμένα από μια κανονική ένωση. Αυτό οδηγεί σε πιο σταθερή απόδοση σύνδεσης όπως αναλύεται παρακάτω.
Είδαμε επίσης μειωμένη χρήση πόρων σε άλλους φόρτους εργασίας παραγωγής μας υπό πειραματισμό. Σε μια περίοδο δύο εβδομάδων και στους πέντε φόρτους εργασίας, η προσέγγιση Learned Bloom Filter δημιούργησε έναν μέσο όρο ημερήσια εξοικονόμηση κόστους του 25%, το οποίο επίσης αντιπροσωπεύει την εκπαίδευση μοντέλων και τη δημιουργία ευρετηρίου.
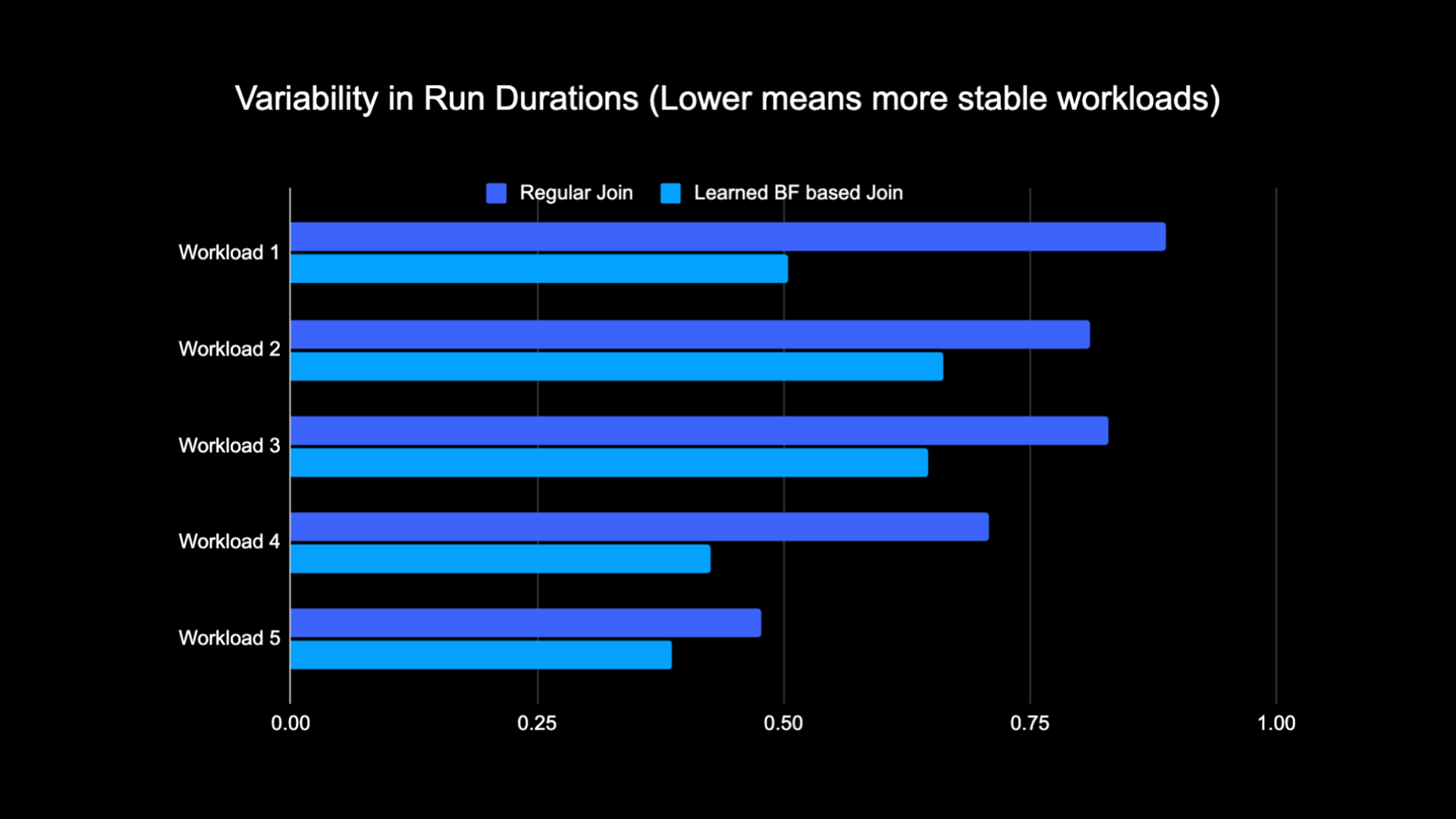
Λόγω του μειωμένου όγκου των δεδομένων που ανακατεύτηκαν κατά την εκτέλεση της σύνδεσης, μπορέσαμε να μειώσουμε σημαντικά το λειτουργικό κόστος της διοχέτευσης αναλυτικών στοιχείων, ενώ παράλληλα το κάναμε πιο σταθερό. Το παρακάτω γράφημα δείχνει τη μεταβλητότητα (χρησιμοποιώντας έναν συντελεστή διακύμανσης) στις διάρκειες εκτέλεσης (τοίχος ώρα ρολογιού) για κανονικό φόρτο εργασίας σύνδεσης και φόρτο εργασίας βάσει φίλτρου μάθησης άνθισης σε περίοδο δύο εβδομάδων για τους πέντε φόρτους εργασίας με τους οποίους πειραματιστήκαμε. Οι εκτελέσεις που χρησιμοποιούσαν τα φίλτρα Learned Bloom ήταν πιο σταθερές—πιο συνεπείς σε διάρκεια—που ανοίγει τη δυνατότητα μετακίνησής τους σε φθηνότερους παροδικούς αναξιόπιστους υπολογιστικούς πόρους.
βιβλιογραφικές αναφορές
[1] T. Kraska, A. Beutel, EH Chi, J. Dean και Ν. Πολυζώτης. The Case for Learned Index Structures. https://arxiv.org/abs/1712.012082017.
[2] Μ. Mitzenmacher. Βελτιστοποίηση φίλτρων μαθημένης άνθισης με σάντουιτς.
https://arxiv.org/abs/1803.014742018.
¹Από 3 μήνες που έληξαν στις 30 Ιουνίου 2023
²Από 3 μήνες που έληξαν στις 30 Ιουνίου 2023
[ad_2]
Source link

